I am currently undertaking research in four areas: (a) 3D scene reconstruction and semantic segmentation, (b) 2D shape detection, (c) segmentation hierarchy editing and (d) visual object tracking.
3D Scene Reconstruction and Semantic Segmentation
| Let’s Take This Online: Adapting Scene Coordinate Regression Network Predictions for Online RGB-D Camera Relocalisation 3DV (oral), September 2019 Preprint Link, arXiv Link |
| Tommaso Cavallari*, Luca Bertinetto, Jishnu Mukhoti, Philip Torr and Stuart Golodetz* |
| Many applications require a camera to be relocalised online, without expensive offline training on the target scene. Whilst both keyframe and sparse keypoint matching methods can be used online, the former often fail away from the training trajectory, and the latter can struggle in textureless regions. By contrast, scene coordinate regression (SCoRe) methods generalise to novel poses and can leverage dense correspondences to improve robustness, and recent work has shown how to adapt SCoRe forests between scenes, allowing their state-of-the-art performance to be leveraged online. However, because they use features hand-crafted for indoor use, they do not generalise well to harder outdoor scenes. Whilst replacing the forest with a neural network and learning suitable features for outdoor use is possible, the techniques used to adapt forests between scenes are unfortunately harder to transfer to a network context. In this paper, we address this by proposing a novel way of leveraging a network trained on one scene to predict points in another scene. Our approach replaces the appearance clustering performed by the branching structure of a regression forest with a two-step process that first uses the network to predict points in the original scene, and then uses these predicted points to look up clusters of points from the new scene. We show experimentally that our online approach achieves state-of-the-art performance on both the 7-Scenes and Cambridge Landmarks datasets, whilst running in under 300ms, making it highly effective in live scenarios. |
| Real-Time RGB-D Camera Pose Estimation in Novel Scenes using a Relocalisation Cascade TPAMI, May 2019 Publication Link, Preprint Link, Supplementary Material Link, arXiv Preprint Link |
| Tommaso Cavallari*, Stuart Golodetz*, Nicholas A. Lord*, Julien Valentin*, Victor A. Prisacariu, Luigi Di Stefano and Philip H. S. Torr |
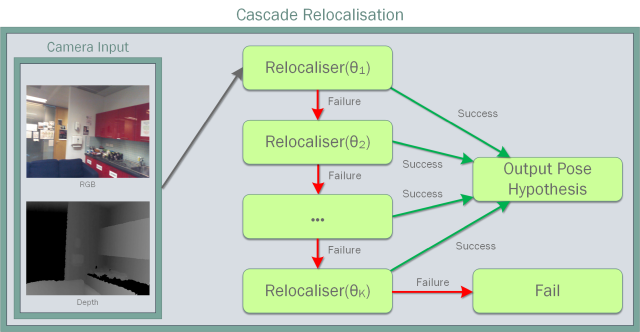 |
| Camera pose estimation is an important problem in computer vision, with applications as diverse as simultaneous localisation and mapping, virtual/augmented reality and navigation. Common techniques match the current image against keyframes with known poses coming from a tracker, directly regress the pose, or establish correspondences between keypoints in the current image and points in the scene in order to estimate the pose. In recent years, regression forests have become a popular alternative to establish such correspondences. They achieve accurate results, but have traditionally needed to be trained offline on the target scene, preventing relocalisation in new environments. Recently, we showed how to circumvent this limitation by adapting a pre-trained forest to a new scene on the fly. The adapted forests achieved relocalisation performance that was on par with that of offline forests, and our approach was able to estimate the camera pose in close to real time, which made it desirable for systems that require online relocalisation. In this paper, we present an extension of this work that achieves significantly better relocalisation performance whilst running fully in real time. To achieve this, we make several changes to the original approach: (i) instead of simply accepting the camera pose hypothesis produced by RANSAC without question, we make it possible to score the final few hypotheses it considers using a geometric approach and select the most promising one; (ii) we chain several instantiations of our relocaliser (with different parameter settings) together in a cascade, allowing us to try faster but less accurate relocalisation first, only falling back to slower, more accurate relocalisation as necessary; and (iii) we tune the parameters of our cascade, and the individual relocalisers it contains, to achieve effective overall performance. Taken together, these changes allow us to significantly improve upon the performance our original state-of-the-art method was able to achieve on the well-known 7-Scenes and Stanford 4 Scenes benchmarks. As additional contributions, we present a novel way of visualising the internal behaviour of our forests, and use the insights gleaned from this to show how to entirely circumvent the need to pre-train a forest on a generic scene. |
| Collaborative Large-Scale Dense 3D Reconstruction with Online Inter-Agent Pose Optimisation TVCG, November 2018 Torr Vision Group Link, Preprint Link, Supplementary Material Link, arXiv Preprint Link |
| Stuart Golodetz*, Tommaso Cavallari*, Nicholas A. Lord*, Victor A. Prisacariu, David W. Murray and Philip H. S. Torr |
  |
| Reconstructing dense, volumetric models of real-world 3D scenes is important for many tasks, but capturing large scenes can take significant time, and the risk of transient changes to the scene goes up as the capture time increases. These are good reasons to want instead to capture several smaller sub-scenes that can be joined to make the whole scene. Achieving this has traditionally been difficult: joining sub-scenes that may never have been viewed from the same angle requires a high-quality relocaliser that can cope with novel poses, and tracking drift in each sub-scene can prevent them from being joined to make a consistent overall scene. Recent advances in mobile hardware, however, have significantly improved our ability to capture medium-sized sub-scenes with little to no tracking drift. Moreover, high-quality regression forest-based relocalisers have recently been made more practical by the introduction of a method to allow them to be trained and used online. In this paper, we leverage these advances to present what to our knowledge is the first system to allow multiple users to collaborate interactively to reconstruct dense, voxel-based models of whole buildings. Using our system, an entire house or lab can be captured and reconstructed in under half an hour using only consumer-grade hardware. |
| Probabilistic Object Reconstruction with Online Global Model Correction 3DV (spotlight), October 2017 Link |
| Jack Hunt, Victor A. Prisacariu, Stuart Golodetz, Tommaso Cavallari, Nicholas A. Lord and Philip H. S. Torr |
| In recent years, major advances have been made in 3D scene reconstruction, with a number of approaches now able to yield dense, globally-consistent models at scale. However, much less progress has been made for objects, which can exhibit far fewer unambiguous geometric/texture cues than a full scene, and thus are much harder to track against. In this work, we present a novel probabilistic object reconstruction framework that simultaneously allows for online, implicit deformation of the object’s surface to reduce tracking drift and handle loop closure events. Coupled with our probabilistic formulation is the use of a multiple sub-segment representation of the object, used to enforce global consistency, with segmentation of the object built in to the formulation. Finally, we employ a CRF framework to refine the overall segmentation, defined by a probability field over the object. We present compelling improvements over the current state-of-the-art reconstruction work and demonstrate robustness and consistency w.r.t. established dense SLAM frameworks. |
| On-the-Fly Adaptation of Regression Forests for Online Camera Relocalisation CVPR (oral), July 2017 Torr Vision Group Link, Publication Link, Preprint Link |
| Tommaso Cavallari, Stuart Golodetz*, Nicholas A. Lord*, Julien Valentin, Luigi Di Stefano and Philip H. S. Torr |
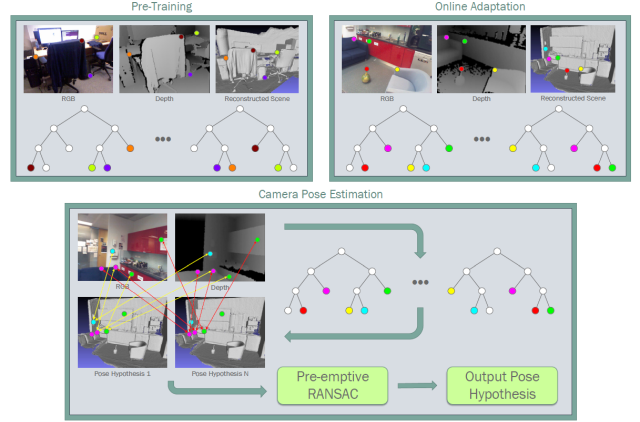 |
| Camera relocalisation is a key problem in computer vision, with applications as diverse as simultaneous localisation and mapping, virtual/augmented reality and navigation. Common techniques either match the current image against keyframes with known poses coming from a tracker, or establish 2D-to-3D correspondences between keypoints in the current image and points in the scene in order to estimate the camera pose. Recently, regression forests have become a popular alternative to establish such correspondences. They achieve accurate results, but must be trained offline on the target scene, preventing relocalisation in new environments. In this paper, we show how to circumvent this limitation by adapting a pre-trained forest to a new scene on the fly. Our adapted forests achieve relocalisation performance that is on par with that of offline forests, and our approach runs in under 150ms, making it desirable for real-time systems that require online relocalisation. |
| Joint Object-Material Category Segmentation from Audio-Visual Cues BMVC, September 2015 (Link) |
| Anurag Arnab, Michael Sapienza, Stuart Golodetz, Julien Valentin, Ondrej Miksik, Shahram Izadi and Philip H. S. Torr |
 |
| It is not always possible to recognise objects and infer material properties for a scene from visual cues alone, since objects can look visually similar whilst being made of very different materials. In this paper, we therefore present an approach that augments the available dense visual cues with sparse auditory cues in order to estimate dense object and material labels. Since estimates of object class and material properties are mutually-informative, we optimise our multi-output labelling jointly using a random-field framework. We evaluate our system on a new dataset with paired visual and auditory data that we make publicly available. We demonstrate that this joint estimation of object and material labels significantly outperforms the estimation of either category in isolation. |
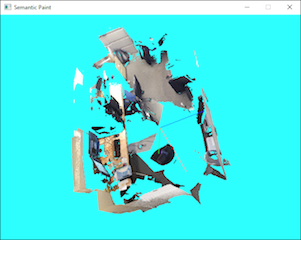
| SemanticPaint: Interactive Segmentation and Learning of 3D Worlds SIGGRAPH Emerging Technologies, August 2015 Torr Vision Group Link, Abstract Link, Conference Link, Technical Report Link |
| Stuart Golodetz*, Michael Sapienza*, Julien P. C. Valentin, Vibhav Vineet, Ming-Ming Cheng, Victor A. Prisacariu, Olaf Kahler, Carl Yuheng Ren, Anurag Arnab, Stephen L. Hicks, David W. Murray, Shahram Izadi and Philip H. S. Torr |
 |
| We present a real-time, interactive system for the geometric reconstruction, object-class segmentation and learning of 3D scenes. Using our system, a user can walk into a room wearing a depth camera and a virtual reality headset, and both densely reconstruct the 3D scene and interactively segment the environment into object classes such as ‘chair’, ‘floor’ and ‘table’. The user interacts physically with the real-world scene, touching objects and using voice commands to assign them appropriate labels. These user-generated labels are leveraged by an online random forest-based machine learning algorithm, which is used to predict labels for previously unseen parts of the scene. The predicted labels, together with those provided directly by the user, are incorporated into a dense 3D conditional random field model, over which we perform mean-field inference to filter out label inconsistencies. The entire pipeline runs in real time, and the user stays ‘in the loop’ throughout the process, receiving immediate feedback about the progress of the labelling and interacting with the scene as necessary to refine the predicted segmentation. |
| Incremental Dense Semantic Stereo Fusion for Large-Scale Semantic Scene Reconstruction ICRA, May 2015 (Link) Robot Vision Best Paper Award – Finalist |
| Vibhav Vineet*, Ondrej Miksik*, Morten Lidegaard, Matthias Niessner, Stuart Golodetz, Victor A Prisacariu, Olaf Kahler, David Murray, Shahram Izadi, Patrick Pérez and Philip H. S. Torr |
 |
| Our abilities in scene understanding, which allow us to perceive the 3D structure of our surroundings and intuitively recognise the objects we see, are things that we largely take for granted, but for robots, the task of understanding large scenes quickly remains extremely challenging. Recently, scene understanding approaches based on 3D reconstruction and semantic segmentation have become popular, but existing methods either do not scale, fail outdoors, provide only sparse reconstructions or are rather slow. In this paper, we build on a recent hash-based technique for large-scale fusion and an efficient mean-field inference algorithm for densely-connected CRFs to present what to our knowledge is the first system that can perform dense, large-scale, outdoor semantic reconstruction of a scene in (near) real time. We also present a ‘semantic fusion’ approach that allows us to handle dynamic objects more effectively than previous approaches. We demonstrate the effectiveness of our approach on the KITTI dataset, and provide qualitative and quantitative results showing high-quality dense reconstruction and labelling of a number of scenes. |
| The Semantic Paintbrush: Interactive 3D Mapping and Recognition in Large Outdoor Spaces CHI, April 2015 (Link) |
| Ondrej Miksik*, Vibhav Vineet*, Morten Lidegaard, Matthias Niessner, Ramprasaath Selvaraju, Stuart Golodetz, Shahram Izadi, Stephen L Hicks, Patrick Pérez and Philip H. S. Torr |
 |
| We present an augmented reality system for large scale 3D reconstruction and recognition in outdoor scenes. Unlike existing prior work, which tries to reconstruct scenes using active depth cameras, we use a purely passive stereo setup, allowing for outdoor use and extended sensing range. Our system not only produces a map of the 3D environment in real-time, it also allows the user to draw (or ‘paint’) with a laser pointer directly onto the reconstruction to segment the model into objects. Given these examples our system then learns to segment other parts of the 3D map during online acquisition. Unlike typical object recognition systems, ours therefore very much places the user ‘in the loop’ to segment particular objects of interest, rather than learning from predefined databases. The laser pointer additionally helps to ‘clean up’ the stereo reconstruction and final 3D map, interactively. Using our system, within minutes, a user can capture a full 3D map, segment it into objects of interest, and refine parts of the model during capture. We provide full technical details of our system to aid replication, as well as quantitative evaluation of system components. We demonstrate the possibility of using our system for helping the visually impaired navigate through spaces. |
2D Shape Detection
| Straight to Shapes: Real-time Detection of Encoded Shapes CVPR, July 2017 Torr Vision Group Link, Publication Link, Preprint Link |
| Saumya Jetley*, Michael Sapienza*, Stuart Golodetz and Philip H. S. Torr |
 |
| Current object detection approaches predict bounding boxes, but these provide little instance-specific information beyond location, scale and aspect ratio. In this work, we propose to directly regress to objects’ shapes in addition to their bounding boxes and categories. It is crucial to find an appropriate shape representation that is compact and decodable, and in which objects can be compared for higher-order concepts such as view similarity, pose variation and occlusion. To achieve this, we use a denoising convolutional auto-encoder to establish an embedding space, and place the decoder after a fast end-to-end network trained to regress directly to the encoded shape vectors. This yields what to the best of our knowledge is the first real-time shape prediction network, running at 35 FPS on a high-end desktop. With higher-order shape reasoning well-integrated into the network pipeline, the network shows the useful practical quality of generalising to unseen categories that are similar to the ones in the training set, something that most existing approaches fail to handle. |
Segmentation Hierarchy Editing
| Simplifying TugGraph using Zipping Algorithms Accepted to Pattern Recognition, February 2020 Publication Link Author’s Version Link Supplementary Material Link |
| Stuart Golodetz, Anurag Arnab, Irina Voiculescu and Stephen Cameron |
|
Graphs are an invaluable modelling tool in many domains, but visualising large graphs in their entirety can be difficult. Hierarchical graph visualisation – recursively clustering a graph’s nodes to view it at a higher level of abstraction – has thus become popular. However, this can hide important information that a user needs to understand a graph’s topology, e.g. nodes’ neighbourhoods. TugGraph addressed this by ‘separating out’ a given node’s neighbours from their hierarchy ancestors to visualise them independently. Its original implementation was straightforward, but copied parts of the hierarchy, making it slow and memory-hungry. An optimised later version, which we refer to as FastTug, avoided this, but at a cost in clarity. Optimising TugGraph without sacrificing clarity is difficult because of the need to keep every hierarchy node connected, a common challenge for graph hierarchy editing algorithms. Recently, this problem has been addressed by ‘zipping’ algorithms, multi-level split/merge algorithms that preserve hierarchy node connectedness and can be built upon for higher-level editing. In this paper, we generalise the original unzipping algorithms to implement SimpleTug, a simple, modular version of TugGraph that is easy to understand and implement, and even faster and more memory-efficient than FastTug. We formally prove its equivalence to FastTug, and show how both can be parallelised. Using our millipede hierarchical image segmentation system, we show experimentally that both the serial and parallel versions of SimpleTug are around 25% faster than their FastTug counterparts, whilst using considerably less memory. Finally, we discuss the interesting theoretical connections between TugGraph and zipping, and suggest ideas for further work. |
| Simpler Editing of Graph-Based Segmentation Hierarchies using Zipping Algorithms Pattern Recognition, October 2017 Publication Link Preprint Link Supplementary Material Link |
| Stuart Golodetz, Irina Voiculescu and Stephen Cameron |
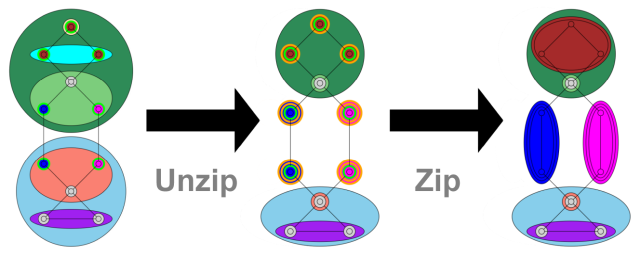 |
| Graph-based image segmentation is popular, because graphs can naturally represent image parts and the relationships between them. Whilst many single-scale approaches exist, significant interest has been shown in segmentation hierarchies, which represent image objects at different scales. However, segmenting arbitrary images automatically remains elusive: segmentation is under-specified, with different users expecting different outcomes. Hierarchical segmentation compounds this, since it is unclear where in the hierarchy objects should appear. Users can easily edit flat segmentations to influence the outcome, but editing hierarchical segmentations is harder: indeed, many existing interactive editing techniques make only small, local hierarchy changes. In this paper, we address this by introducing ‘zipping’ operations for segmentation hierarchies to facilitate user interaction. We use these operations to implement algorithms for non-sibling node merging and parent switching, and perform experiments on both 2D and 3D images to show that these latter algorithms can significantly reduce the interaction burden on the user. |
Visual Object Tracking
| Staple: Complementary Learners for Real-Time Tracking CVPR, June 2016 Publication Link Preprint Link arXiv Link Project Page Link |
| Luca Bertinetto, Jack Valmadre, Stuart Golodetz, Ondrej Miksik and Philip H. S. Torr |
 |
| Correlation Filter-based trackers have recently achieved excellent performance, showing great robustness to challenging situations such as motion blur and illumination changes. However, since the model that they learn depends strongly on the spatial layout of the tracked object, they are notoriously sensitive to deformation. Models based on colour statistics have complementary traits: they cope well with variation in shape, but suffer when illumination is not consistent throughout a sequence. Moreover, colour distributions alone can be insufficiently discriminative. In this paper, we show that a simple tracker combining complementary cues in a ridge regression framework can operate faster than 90 FPS and outperform not only all entries in the popular VOT14 competition, but also recent and far more sophisticated trackers according to multiple benchmarks. |
| Struck: Structured Output Tracking with Kernels TPAMI, October 2016 (accepted for publication December 2015) Publication Link Author’s Version Link Supplementary Material Link YouTube Channel |
| Sam Hare*, Stuart Golodetz*, Amir Saffari*, Vibhav Vineet, Ming-Ming Cheng, Stephen L. Hicks and Philip H. S. Torr |
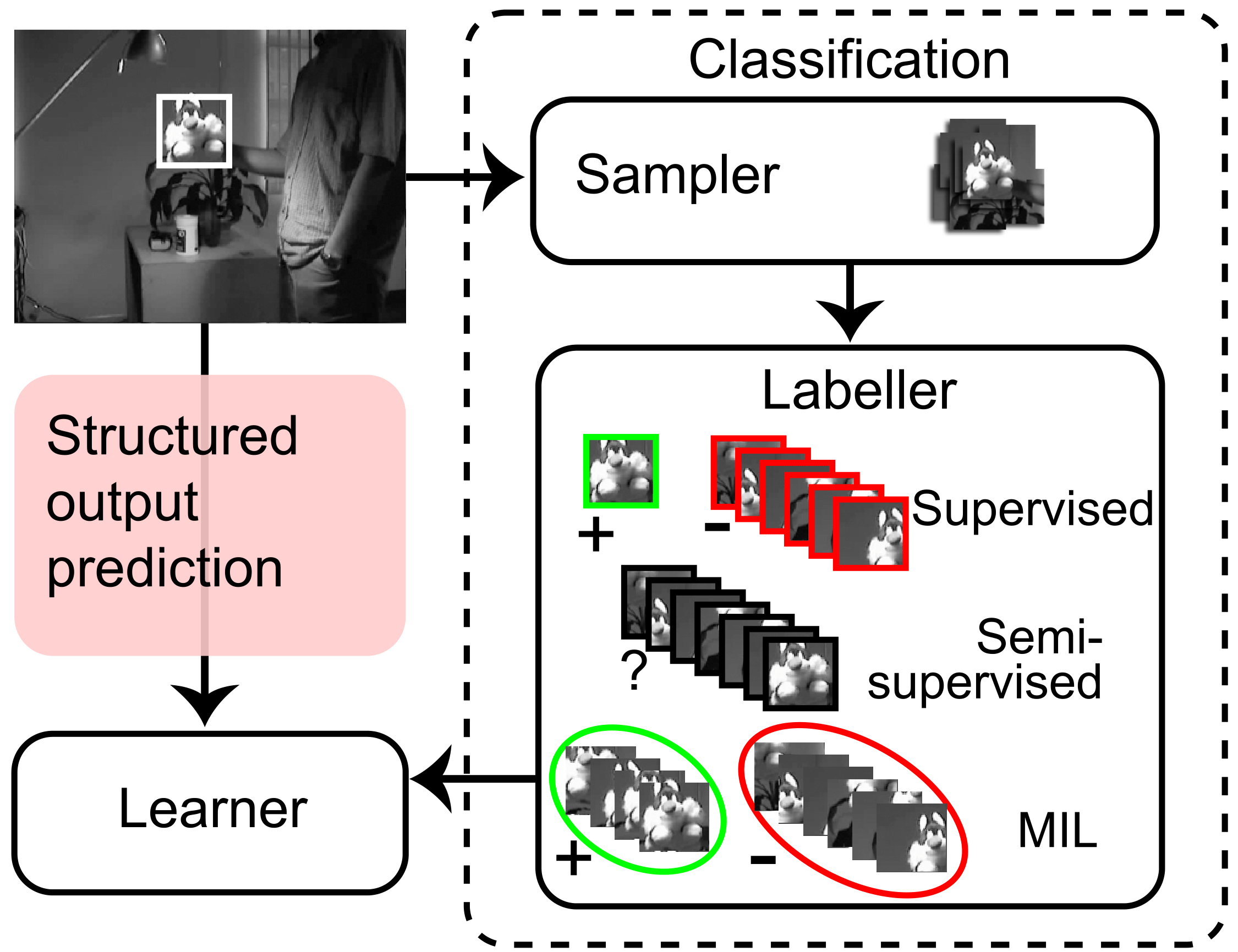 |
| Adaptive tracking-by-detection methods are widely used in computer vision for tracking arbitrary objects. Current approaches treat the tracking problem as a classification task and use online learning techniques to update the object model. However, for these updates to happen one needs to convert the estimated object position into a set of labelled training examples, and it is not clear how best to perform this intermediate step. Furthermore, the objective for the classifier (label prediction) is not explicitly coupled to the objective for the tracker (estimation of object position). In this paper, we present a framework for adaptive visual object tracking based on structured output prediction. By explicitly allowing the output space to express the needs of the tracker, we avoid the need for an intermediate classification step. Our method uses a kernelised structured output support vector machine (SVM), which is learned online to provide adaptive tracking. To allow our tracker to run at high frame rates, we (a) introduce a budgeting mechanism that prevents the unbounded growth in the number of support vectors that would otherwise occur during tracking, and (b) show how to implement tracking on the GPU. Experimentally, we show that our algorithm is able to outperform state-of-the-art trackers on various benchmark videos. Additionally, we show that we can easily incorporate additional features and kernels into our framework, which results in increased tracking performance. |