Tommaso Cavallari*, Stuart Golodetz*, Nicholas A Lord*, Julien Valentin*, Victor A Prisacariu, Luigi Di Stefano and Philip H S Torr
Abstract
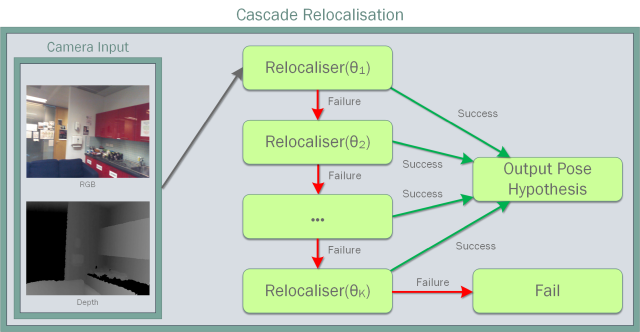
Camera pose estimation is an important problem in computer vision. Common techniques either match the current image against keyframes with known poses, directly regress the pose, or establish correspondences between keypoints in the image and points in the scene to estimate the pose. In recent years, regression forests have become a popular alternative to establish such correspondences. They achieve accurate results, but have traditionally needed to be trained offline on the target scene, preventing relocalisation in new environments. Recently, we showed how to circumvent this limitation by adapting a pre-trained forest to a new scene on the fly. The adapted forests achieved relocalisation performance that was on par with that of offline forests, and our approach was able to estimate the camera pose in close to real time. In this paper, we present an extension of this work that achieves significantly better relocalisation performance whilst running fully in real time. To achieve this, we make several changes to the original approach: (i) instead of accepting the camera pose hypothesis without question, we make it possible to score the final few hypotheses using a geometric approach and select the most promising; (ii) we chain several instantiations of our relocaliser together in a cascade, allowing us to try faster but less accurate relocalisation first, only falling back to slower, more accurate relocalisation as necessary; and (iii) we tune the parameters of our cascade to achieve effective overall performance. These changes allow us to significantly improve upon the performance our original state-of-the-art method was able to achieve on the well-known 7-Scenes and Stanford 4 Scenes benchmarks. As additional contributions, we present a way of visualising the internal behaviour of our forests and show how to entirely circumvent the need to pre-train a forest on a generic scene.